RoboVQA: Multimodal Long-Horizon Reasoning
for Robotics
- Pierre Sermanet, Tianli Ding, Jeffrey Zhao, Fei Xia, Debidatta Dwibedi, Keerthana Gopalakrishnan, Christine Chan, Gabriel Dulac-Arnold, Sharath Maddineni, Nikhil J Joshi, Pete Florence, Wei Han, Robert Baruch, Yao Lu, Suvir Mirchandani, Peng Xu, Pannag Sanketi, Karol Hausman, Izhak Shafran, Brian Ichter, Yuan Cao
Scaling up RoboVQA with Google Meet
Video conference tools like Google Meet provides powerful infrastructure for realtime video streaming, multi-participant support and high quality speech transcription. This helps scaling up data collection and deployment to anywhere, with any embodiment, while removing the requirement for a mouse + keyboard interface
2- Demonstrating 6 VQA task types: planning, success, discriminative affordance, generative affordance, past description and future prediction
Notes: The cognitive model "Brain" is being evaluated here on a pre-recorded video with human teleoperation (100% physical intervention). The intervention only evaluates the planning answers in this video. The other types of questions asked by the user are not used by the robot to make closed-loop decisions about planning. These questions however could be used by the robot for increased robustness to self-check planning decisions (for example checking for success and retrying until success is detected). Planning questions are asked at pre-determined points in the video (obtained from hindsight temporal segmentations). In this video, we observe that the cognitive model was able to correctly identify if instructions ("pick up the bag", "pick up the cap") were satisfied or not before and after being performed.
3- Example of Evaluation #1: Autonomous cognition model with human teleoperation
Main Quantitative Results
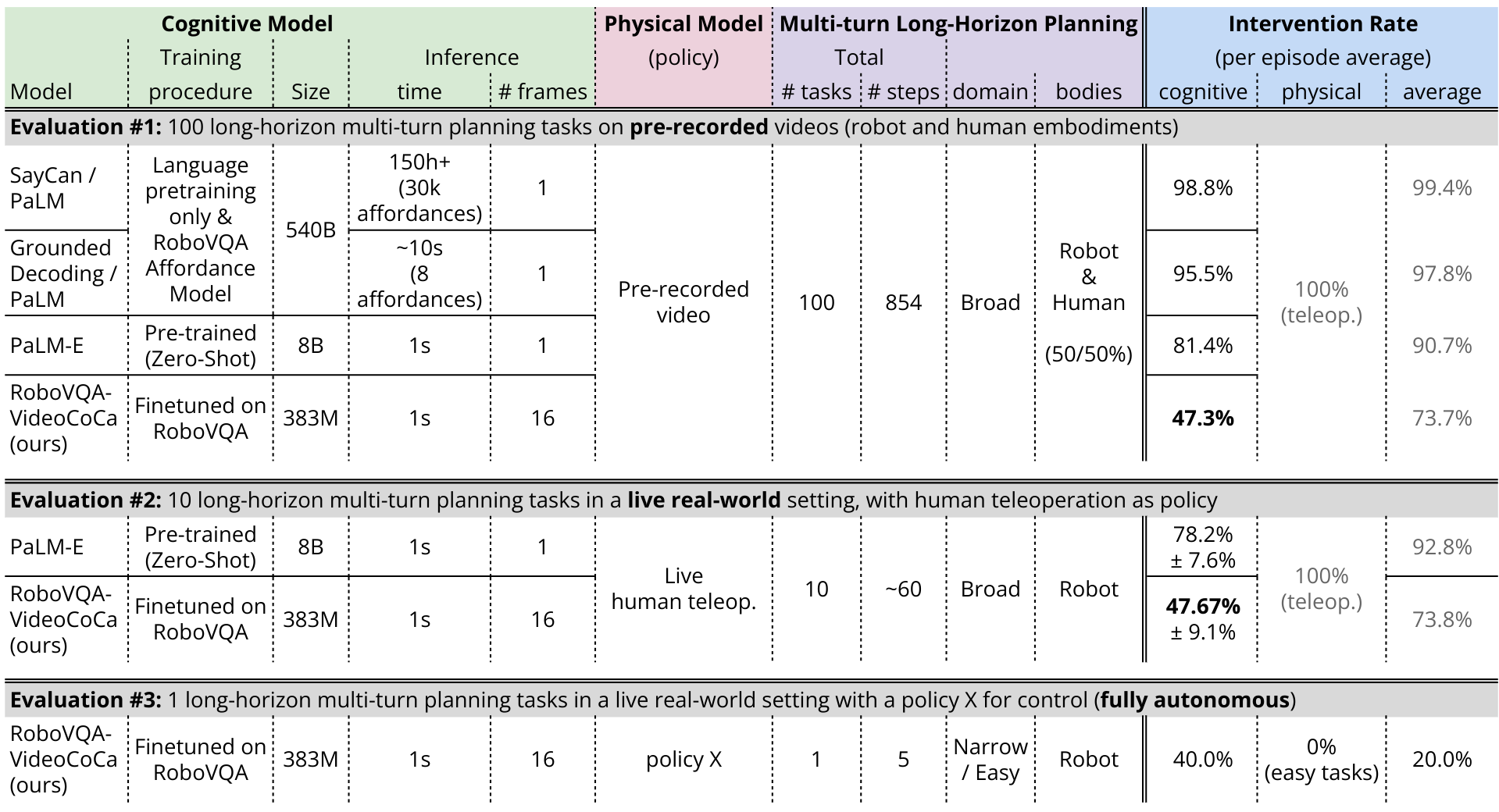
In the Table 1 below we report 3 long-horizon planning evaluations where a model has to predict the next task to perform at multiple turns given a long-horizon instruction and the last few seconds of video. The metric used here is human intervention rate, which we decompose into "cognitive" (high-level reasoning) and "physical" for actual control. This allows us to evaluate the full breadth of the cognitive model which is much broader than what our low-level policy can achieve.
Evaluation #1 evaluates models on 100 existing long-horizon episodes (854 planning steps to predict in total) in a broad domain (various tasks across 3 office buildings). This evaluation considers all 3 embodiments contained in the dataset (robot, human, human with tool). Evaluations #2 and #3 however only consider the robot embodiment.
Evaluation #2 is exploring how a high-level cognitive model can actually command a real robot through long-horizon planning. To remain in the broad domain, we use human teleoperation for control and hence avoid more limited domain that our current policies can perform.
Finally, in evaluation #3 we show that combining a high-level cognitive model with a low-level control policy can lead to a fully autonomous system. The breadth of tasks that can be evaluated however is drastically smaller due to the limited capacities of the policy.
We report the cognitive and physical intervention rates separately because for evaluations #1 and #2, the physical control is performed entirely by humans (hence the average intervention rate cannot be lower than 50%). In evaluation #3 however, we use a policy for control in a fully autonomous setting where the average intervention rate can be <50%.

Dataset
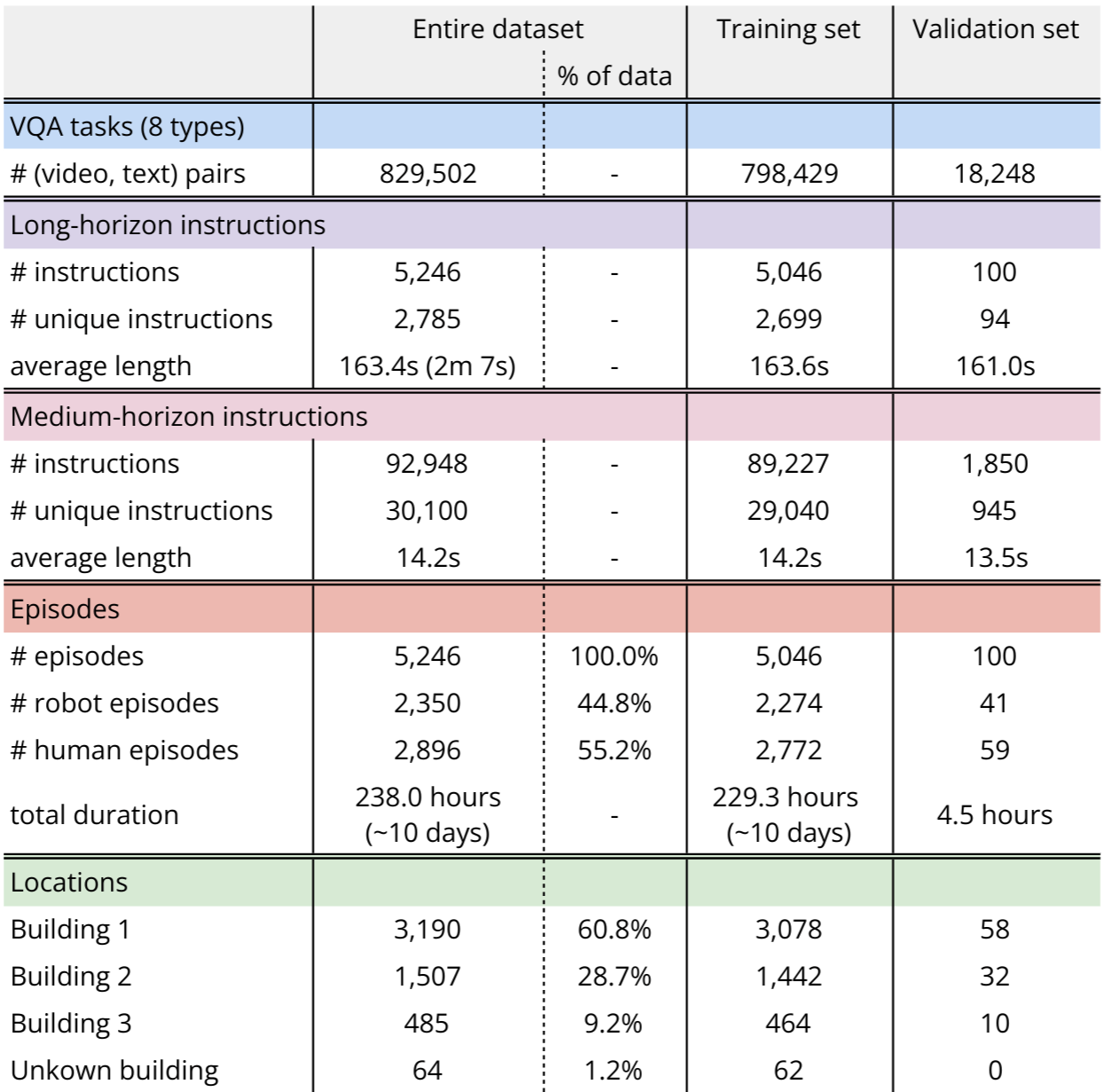
We publicly release the RoboVQA dataset here. It consists of 238h (10 days) of (video, text) pairs coming from recordings of long-horizon instructions being performed by 3 different embodiments (robot, human, human with tool) in a same environment (3 corporate buildings). See statistics for more details.



Videos
We present below some representative long-horizon planning runs by the RoboVQA-VideoCoCa model, ranked by increasing cognitive intervention rate from 0% to 100%. Note that the model is ran on existing pre-recorded videos (with human teleoperation, in other words 100% physical intervention rate), hence some actions are labeled as valid but some other action may be consequently executed in the video instead.
These videos are from the experiment #1 evaluation on the validation set in the results table.
Note that some of the easier tasks are repetitive and simple and usually lead to low intervention scores (see first video). Note also that the intervention labeling is not perfect and some interventions can be incorrect (see last video).
Citation
Acknowledgements
We thank Tran Pham, Elio Prado, Gavin Gonzalez, Jodilyn Peralta, Joseph Dabis, Alex Luong, Jodexty Therlonge, Rochelle Dela Cruz, Brianna Zitkovich, Emily Perez, Eric Tran, Huong T Tran, Dee M, Utsav Malla, Samuel Wan, Justice Carbajal and Scott Lehrer, Joel Magpantay, Sarah Nguyen, Steve Vega and Jonathan Vela for their contributions to data collection.
The website template was borrowed from Jon Barron.